Summary
Unicode is an information technology standard for the consistent , representation, and handling of text expressed in most of the world’s writing systems. The standard is maintained by the Unicode Consortium, and as of March 2020, it has a total of 143,859 characters, with Unicode 13.0 (these characters consist of 143,696 graphic characters and 163 format characters) covering 154 modern and historic scripts, as well as multiple symbol sets and emoji.
Summary, technical fc
| position | ease | box | interval | due |
|---|---|---|---|---|
| front | 2.5 | 0 | 0 | 2021-10-31T09:59:35Z |
Code Unit
A code unit is the number of bits an encoding uses. So UTF-8 would use 8 and UTF-16 would use 16 units. code unit are 8 and 16 respectively.
Codepoint(character)
A codepoint is a character and this is represented by one or more code units depending on the encoding. Identity of a character is a codepoint not raw bytes.
(Binary)(codepoints or characters to bytes)
str -> bytes (encode)
- (Encoding: human understand string char and computer bytes, so encoding strings as
bytes)
- by default in python strings are encoded using “utf-8”
bytes -> str (decode)
- (Decoding: computer language to human language)
And
is an algorithm that converts codepoint into bytes sequence vice verca.
f(x) = y
# f -> enconding algorithm
# x -> human language character
# y -> computer language character(binary digits)
perspective
original = '27岁少妇生孩子后变老'
type(original)
<class 'str'>
encoded = original.encode('utf-8') # convertin string to bytes
print(encoded)
b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'
type(encoded)
<class 'bytes'>
# str -> bytes is encoding in python context
encoded2 = bytes(original, 'utf-8')
# bytes -> str is decoding in python context
print(encoded2)
b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'
# decoding(from bytes to characters)
# decoding: from bytes to something understandable
decoded = encoded.decode('utf-8')
print(decoded)
27岁少妇生孩子后变老
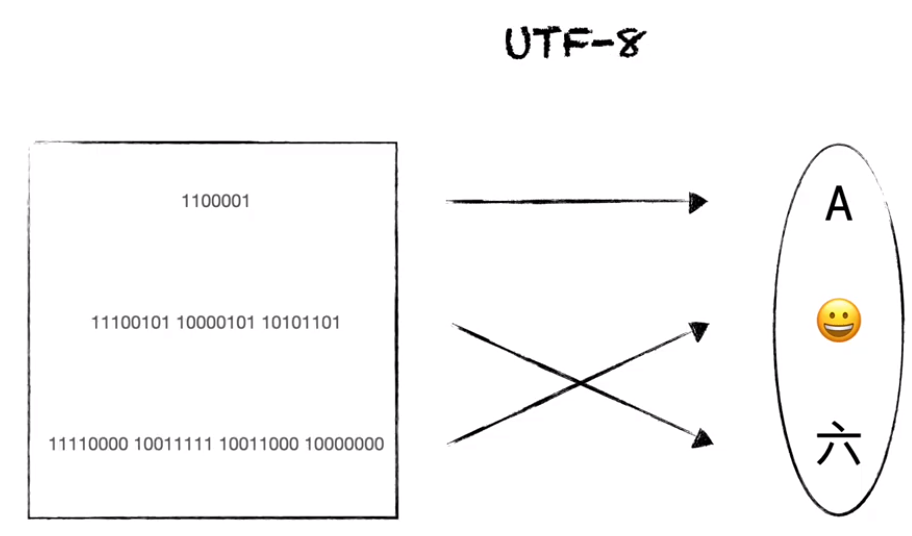
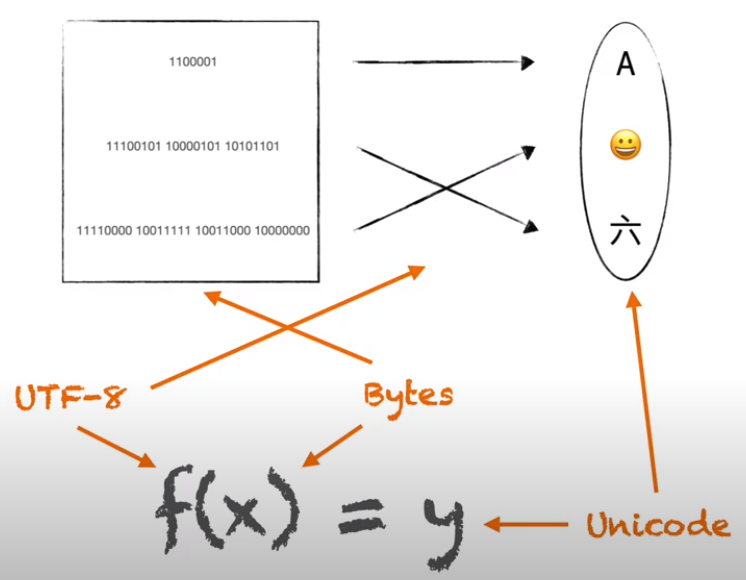
Decoding
Converting from bytes to code point is decoding. bytes -> codepoint(human understandable characters)
Codepoints are integers:
Codepoint of character ‘a’ is U+0061 which is integer 97 Codepoint of ‘ä’ is U+00E4, which is integer 228 codepoints have different byte sequence in different encoding