:ID: 4c47a1f6-17d9-4987-aebd-2a08ede644e3
OCR tools Evaluation
easyocr
(pyvenv-workon "tawakkalna_env")
import os
import easyocr
reader = easyocr.Reader(['en'], gpu = False)
reader_ar = easyocr.Reader(['ar'], gpu = False)
Loading model into memory
dir_path = "/mnt/data/Dropbox/pictures/tawakkalna/english"
print(dir_path)
image_paths = os.listdir(dir_path)
image_paths = [dir_path + '/' + path for path in image_paths]
dir_path_ar = "/mnt/data/Dropbox/pictures/tawakkalna/arabic"
image_paths_ar = os.listdir(dir_path_ar)
image_paths_ar = [dir_path_ar + '/' + path for path in image_paths_ar]
Testing parsing English
for path in image_paths:
print(path)
result = reader.readtext(path, detail = 0)
print(result)
Testing parsing Arabic
for path in image_paths_ar:
print(path)
result = reader_ar.readtext(path, detail = 0)
print(result)
paddleocr
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `french`, `german`, `korean`, `japan`
# to switch the language model in order.
ocr = PaddleOCR(use_angle_cls=True, lang='en') # need to run only once to download and load model into memory
print(ocr)
for path in image_paths:
print(path)
result = ocr.ocr(path, cls=True)
for line in result:
print(line)
# draw result
# from PIL import Image
# image = Image.open(path).convert('RGB')
# boxes = [line[0] for line in result]
# txts = [line[1][0] for line in result]
# scores = [line[1][1] for line in result]
# im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
# im_show = Image.fromarray(im_show)
# im_show.save('result.jpg')
**
Linux based local solution module dependency diagram
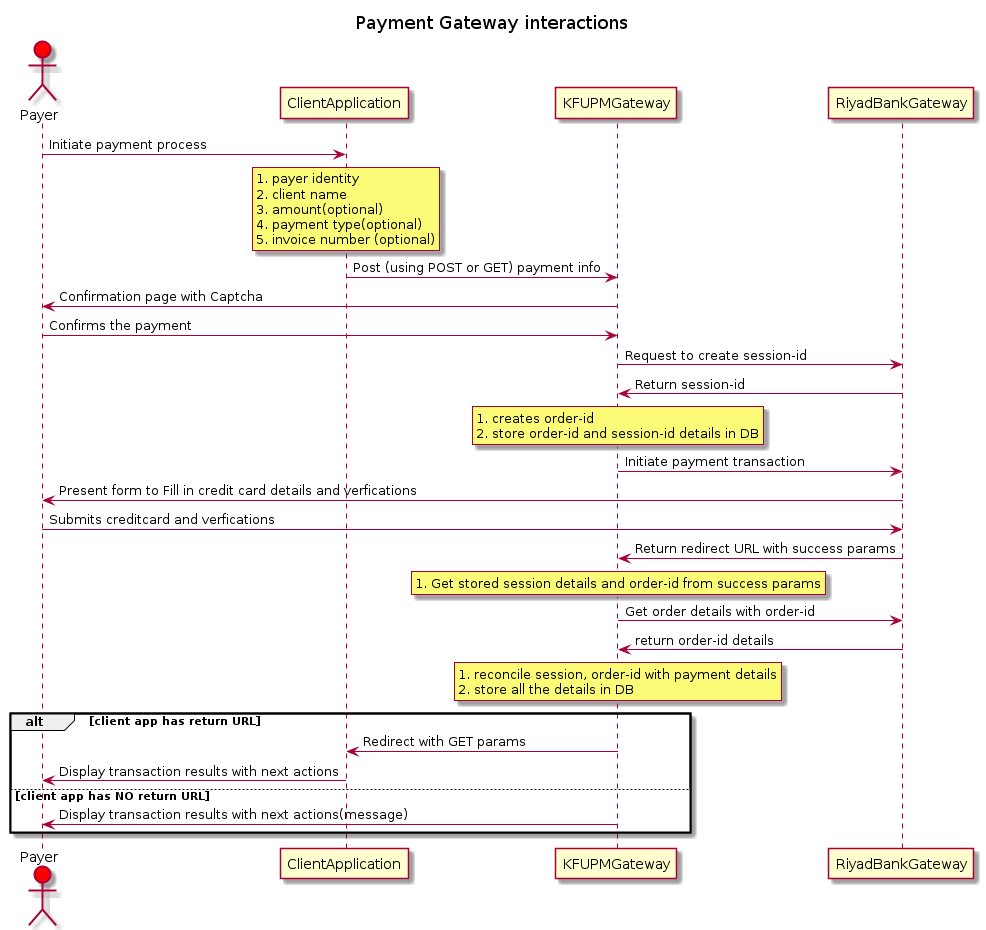
Code reuse architecture
Memebers weekly time
Ali Musa
78hrs Sun to Sat
Arun
25 - 30 hours
Ismail
70 hours Sun to Sat
Ahmed
17 hours